

Former Senior Digital Strategist and Director, Client Success for Acquia CDP Customer Success Acquia
コレクション
セグメンテーションとクラスタリングの違いとは?
Collection :
マーケターがセグメンテーションとクラスタリングを使うようになって久しくなりますが、どちらも消費者行動を観察・予測する上で重要な要素ですが、両者の違いやマーケティングへの影響については、まだ混乱があります。
ここでは、まず一般的に両者について説明しましょう: クラスタリングとセグメンテーションは、どちらも類似性に基づいて人々をグループ化することに関係します。クラスタリングとセグメンテーションは、どちらも類似性に基づいて人々をグループ化するもので、デジタルエクスペリエンスの世界では、予測マーケティングのダイナミック・デュオです。この2つの主な違いは、クラスタリングは一般的に機械学習によって駆動され、セグメンテーションは人間によって駆動されることです。この違いが、クラスタリングを避け、独自の顧客知識に固執する人々を少なからず引き起こしています。
この消極性は、人間対機械というお馴染みの戦いに触れることになります。しかし、セグメンテーションをデータのグループ化の人間版と同じ行為の機械版として見るのではなく、これらの戦術は一緒に使うことができます。二項対立は不要です。実際、おわかりのように、これらは非常に強力に併用することができます。
どちらの戦術も、顧客や見込み客をよりよく理解するのに役立ち、人々があなたの組織とどのように関わっているかを知れば知るほど、彼らが望むものをよりよく提供できるようになります。それは、銀行でお金を稼ぐことであり、良い顧客体験であり、賢いビジネスなのです。
クラスタリングとは何か?
クラスタリングは、機械学習(ML)アルゴリズムを使用して、顧客データの類似性を識別します。簡単に言えば、アルゴリズムが顧客データをレビューし、人間が見逃しているかもしれない類似点を見つけ出し、顧客の行動パターンに基づいて顧客をクラスターに分類する。
例えば、自分でコーディネートしてアパレルを別々に購入するのではなく、視覚的に表示された服をフルで購入する傾向がある買い物客を見つけることなどが挙げられる。別の例としては、キャンペーン時に買いだめするのが好きなビタミンの買い物客と、定期的に補充する買い物客がいる。ビタミン剤や化粧品などを「買いだめ」する人は、長期間買い物に戻ってこないかもしれない。通常のサイクル以外で購入してもらうには、クリエイティブなメッセージやオファーが必要かもしれません。
クラスタリングを使用する場合
機械学習は、コンピューターが自由に使える超能力です。したがって、人間のデータサイエンティストチームでも時間がかかりすぎるような大規模なデータセットを解析したい場合は、クラスタリングを使うのがベストです。クラスタリングはまた、言いたくはないが、人間は誤りを犯しやすいものであり、機械はデータセットの中で私たちが見逃しているものを見抜くかもしれないからです。これによって、顧客データベース全体のクラスターをターゲットにできる可能性があり、より高いレベルでのパーソナライズが可能になります。
マーケティングにクラスタリングを適用する方法
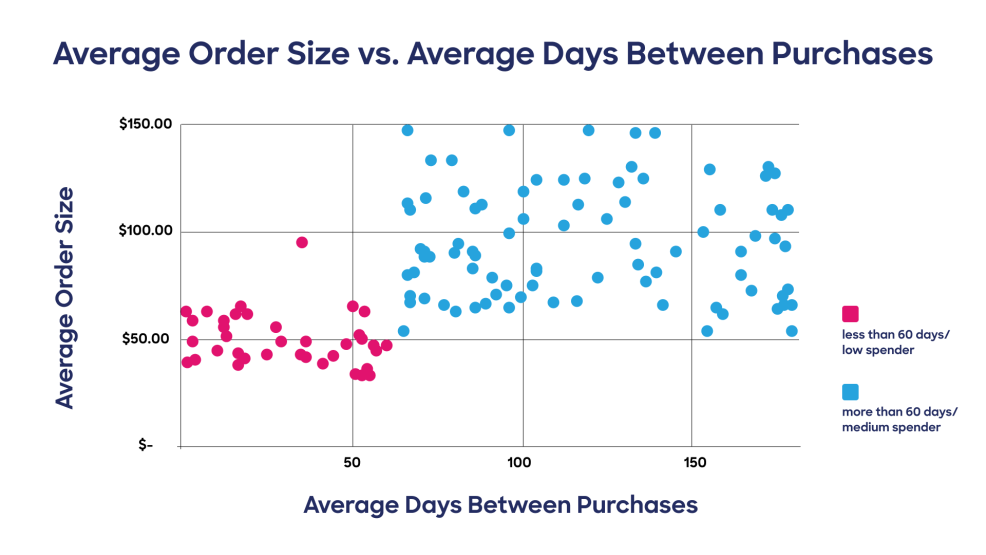
機械学習のクラスタリング・アルゴリズムが、大規模なデータセットから似たようなデータ・グループを見つけ出す簡単な例である。この例では、購入頻度が高い顧客ほど、消費額が少ない。反対に、購入サイクルが長ければ長いほど、消費額は高くなります。購入間隔日数と平均注文サイズを比較すると、このようなデータになります。ストックアップ」バイヤーの例では、このようになります(購入頻度は低いですが、金額はかなり高い)。機械学習クラスタリングアルゴリズムは、類似した行動をとる顧客のクラスタを特定するために、多変量レベルで数十、場合によっては数百のデータポイントにわたってこの比較を行っていることに留意してください。人間がこの規模のタスクを実行することは不可能なのです。
主なポイントは、機械学習がクラスタリングに力を与え、アルゴリズムが類似点を見つけ出すということです。その代わり、マーケティング担当者は、MLが最初の作業を行った後に、どのようなステップを踏むべきかを決定します。
例えば、上記の例では、2回目の注文に60日以上かかるバイヤーのクラスタが特定されました。そのデータを使って、マーケティング担当者はそのクラスターをピンポイントで狙ったキャンペーンを展開することができます。というのも、そのグループの「ストックアップ」バイヤーの購買パターンにこれほど類似性があるのなら、おそらく彼らは他の商品についてもパターン化された行動を共有しているはずだからです。このような場合、マーケティング担当者はこのクラスターに、その購買層が通常購入している商品以外のビタミン剤やサプリメントの割引コードを送ることを検討するかもしれません。
セグメンテーションとは何か?
マーケティング担当者が、大量のデータから特定のグループを抽出する基準を選ぶこと、それがセグメンテーションです。別の言い方をすれば、顧客データを見て、あるグループをターゲットにするための特定の基準を選び出すことです。
セグメンテーションを使用するタイミング
これは、人間が頭を使って、そして奇妙なことに、データから得た心を使って、特定のグループに焦点を当て、望むだけ具体的に掘り下げていくところです。クラスタリングが情報を提供するのに対し、セグメンテーションは力を与え、マーケターがパーソナライズされたメッセージングのために特定のグループを選択し、意図的にターゲットにすることを可能にします。
マーケティングにセグメンテーションを適用する方法
セグメンテーションでは、人間がターゲットを選びます。
もし私がビタミン剤を販売しているのであれば、過去に購入したことのある製品の種類に関連したメッセージで顧客をターゲティングしたいと思うかもしれません。過去に魚油、葉酸、マグネシウムを購入したことのある顧客を、心臓に良いメッセージでセグメントしたいかもしれない。さらに、性別、年齢、生涯消費額を選択することで、そのグループをセグメント化することもできる。同じような購買習慣を持ち、特定のカテゴリーを好む顧客を意図的に特定し、グループ化することは、セグメンテーションの一例である。
セグメンテーションが誤りやすいのは、人間の思い込みにあります。このセグメントは心臓の健康に関心があり、年齢や性別から、より必要性が高いかもしれないので、これらの商品を購入していると仮定する。一方、クラスタリングでは、検討している属性とは関係のない購買行動のパターンを見つけることができる。時には、私たちのバイアスが私たちを惑わすこともある。バイアスは、私たちがターゲットにすべきと考える人々のセグメントを選択するよう私たちを駆り立てます。
クラスタリングにはあらかじめ設定されたバイアスはなく、類似点を求めてデータをクロールするものです。
しかし、このセグメントを特定することは、クラスタリングと併用してオーディエンスを拡大することができるため、依然として重要である。このセグメントへのマーケティング方法をカスタマイズすることで、購入の可能性を高め、ひいてはコンバージョン率を高めることができる。
クラスター分析における機械学習は、常に行動を分析し、顧客を再スコアすることで役立つ。この日々の繰り返しにより、クラスター分析では、ウェブ行動やメールエンゲージメント行動など、人間が日々監視することが不可能な行動の変化を探すことができる。セグメンテーションとクラスタリングは共に強力な味方である。
顧客データプラットフォーム セグメント化とクラスター化に必要なテクノロジー
ビッグデータの台頭により、マーケティング担当者は現在、ブランド嗜好、割引嗜好、サイト滞在時間、閲覧行動など、何百もの特性を調査できるようになりました。顧客特性の中には、購買行動と相関関係のないものもあれば、購買行動とさまざまな形で相関関係のあるものもあります。
しかし、一人の人間(チームであっても)が何百種類ものデータを調べてそれぞれの関係を見つけるのは不可能だ。専任のデータ・サイエンス・チームやMLを可能にする他のテクノロジーがなければ、これは不可能なことです。カスタマー・データ・プラットフォーム(CDPについての詳細は後述する)の機械学習モデルは、クラスター・モデルを通じて買い手の可能性を予測するために、より深く、何千ものデータセットを解析することができます。
しかし、デジタル・プロパティ全体にわたる人間の行動を追跡し、戦略を立て、重複を特定し、データ・ポイントを解決したり組み合わせたりすることは、大変なことです。
ID解決技術はその解決策を提供する。例えば、同一人物が2つの異なるメールアドレスを使用していることを、ID解決によって把握することができる。これは単純な例ですが、この問題を何千倍にもすれば、データの混乱につながることは想像に難くありません。
幸いなことに、こうした問題を解決するテクノロジーがある。先ほども触れたが、カスタマー・データ・プラットフォーム(CDP)は、すべての顧客データを収容・統合し、それに応じてクラスタリングやセグメント化ができる理想的な場所です。CDPがあれば、さまざまな顧客データが異種のシステム間に分散することはありません。その代わりに、360°の顧客プロファイル、つまりパーソナライズされたエクスペリエンスを構築できる行動の最も正確なスナップショットを提供するデータを持つ単一の真実のソースとして機能します。アイデンティティの解決を組み込んだCDPは、特に価値が高いものです。
また、機械学習を搭載したCDPは、パーソナライゼーションの取り組みをダイナミックなものにします。人間は一貫性のある生き物ではないため、その行動データは不可解な場合があります。例えば、CDPは、ブラウジングして実際に何かを購入するユーザーと、"ウィンドウショッピング "してカートに買う予定のないものを詰め込むユーザーとの違いを読み解きます。これを知ることで、マーケティング担当者は、カートをいっぱいにしたままにしていることをやさしく注意喚起したり、一定金額以上の注文に対してクーポンを提供したりするのではなく、購入可能な類似商品を勧めることができます。
そのため、顧客データのプロファイル、クラスター、セグメントは常に調査され、変化を研究し、それに応じて戦略的な意思決定に反映します。機械学習は常に面倒な分析を行ってクラスターを生成し、あなたはセグメントのパラメーターを選択する。どちらの場合も、ダーリン・ヒューマンは、それぞれの戦術が生み出す洞察に基づいて、使用するマーケティング・アプローチを決定します。
次に取るべきステップ
ここでおさらいをしましょう
- セグメンテーション: 大量のデータから、選択した基準を満たす特定のグループを手動で抽出する
- クラスタリング: 機械学習を使用して、顧客データの類似点を特定する
セグメンテーションは人間が定義したグループ分けを行うのに対し、クラスタリングはMLを利用したグループ分けを行うという大きな違いがあります。
現代のビジネスが扱う顧客データの量は驚異的である。クラスタリングとセグメンテーションをうまくマーケティング戦術に組み込むには、データをどのように整理するかにかかっていました。
マーケティング担当者が顧客データ・プラットフォームを使用してデータを整理し、活性化する方法については、E-Book「顧客データの活用方法:データ収集から実践活用まで」をダウンロードしてください: 収集から活性化まで。
Former Senior Digital Strategist and Director, Client Success for Acquia CDP Customer Success Acquia

